


NEWS / AI TECHNOLOGY
25 November 2020
In this article, Amale El Hamri, Senior Data Scientist at Artefact France explains how to train a language model without having understanding the language yourself. The article includes tips on where to get training data from, how much data you need, how to preprocess your data and how to find an architecture and a set of hyperparameters that best suit your model.
TLDR
This article explains how I created my own made language model in Korean, a complex language with limited training data. Here you’ll be able to learn how to train a language model without having the luxury of understanding this language yourself. You’ll find tips on where to get training data from, how much data you need, how to preprocess your data and how to find an architecture and a set of hyperparameters that best suit your model.
My key learnings are:
Data collection:
- When Wikipedia does not have enough volume or that it’s not enough used by native speakers of the language you want to train your language model from, a good thing to do is to combine Wikipedia with other data sources such as CommonCrawl.
Data volume:
- Choose documents that best represent the Korean language. Too many documents would not be useful since the marginal performance improvement would be too small compared to the huge training time.
- Choose documents that contain the most used words in the Korean language.
- Find an architecture that manages to modelise the complexity of the training data.
- Find the right combination of regularization parameters not to overfit.
Introduction
If you don’t know it already, NLP had a huge hype of transfer learning in these past two years. The main idea is to re-use pre-trained language models for another NLP task such as text classification. A language model is a deep learning model that given part of a sentence is able to predict the next word of the sentence. The intuition to understand from this is that this kind of model understands really well the language structure, grammar, vocabulary, and the goal is to ‘transfer’ that knowledge to other downstream models.
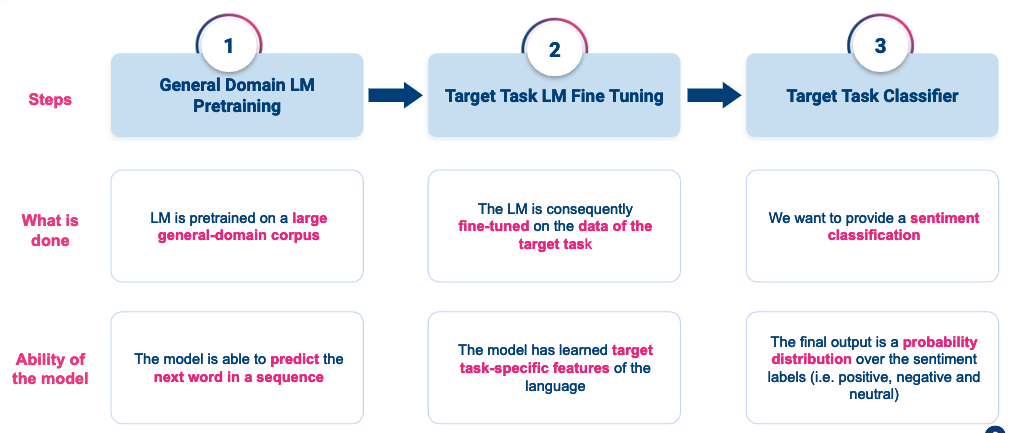
Example: a simple recipe on how to improve a text classifier using fine-tuning
This figure summarises the ULM Fit method that I used for training my language model and therefore fine tune it and transfer it into a text classifier.
- Step 1: Train a general language model on a large corpus of data in the target language. This model will be able to understand the language structure, grammar and main vocabulary.
- Step 2: Fine tune the general language model to the classification training data. Doing that, your model will better learn to represent vocabulary that is used in your training corpus.
- Step 3: Train a text classifier using your fine tuned pretrained language model. This method allows your model to understand the words in their context. Furthermore, using a pretrained language model allows you to train your classifier on very few training examples (as little as 400 texts per label would do the job).
We already know that text classification works nicely on English, French, German, Spanish, Chinese… but what should we do on languages with very few off the shelf language models?
Before going into further details, you may be wondering why a French data scientist like me would want to have a text classifier in Korean? The reason is that I am part of a project that develops a product to classify social media posts into different categories. After validating the methodology on English and French, we started scaling it to other languages (English, French, Japanese, Chinese and korean).
Only there was a bigger challenge in Korean language because there was no pretrained language model to be found in open source so I had to do it myself with very few Korean linguistic resources.
This article will be focusing on Korean text classification by using the multi-fit method explained in the following paper.
A lot of languages are very represented in the web such as: English, Chinese, Spanish, Portuguese, French… Korean language remains very poorly documented and not a lot of content is ready for reuse. So I thought about contributing myself by sharing my key learnings with you, while discovering Korean NLP.
In this article I will tell you about my journey to train a Korean language model without understanding a single word of Korean and how I used it for text classification.
Disclaimer: Usually, we consider a language model as good when it reaches an accuracy of about 45–50%. As my goal is not to generate Korean text, I don’t need to reach such performances: I only need a model that “understands” the grammar and structure of the Korean language so that I can use it to train a Korean text classifier.
1 — Data collection for language model training
1.1 — Data source
Usually, when training a language model from scratch, ULM FiT tutorial suggestions are to download all Wikipedia content in the given language. These guidelines only work if native speakers of this language are used to publishing a lot on this channel.
In Korean, it appears that people are not used to it: not only Wikipedia Korean context has not enough volume, and it is also not representative of native Korean speaking.
Here is a comparison between number of articles in English and Korean Wikipedia to give some hints:

My advice: I combined Wikipedia articles with Common Crawl data that you can download from here.
1.2 — Data volume
Let’s remember that a language model is a model supposed to predict the next word in a text. To do that, our model should have seen a lot of examples to learn the language and be good at speaking it. That being said, it is not useful to go beyond 100 millions of tokens. It only adds complexity to your model as well as a huge training time.
So at first glance, once I had retrieved all Wikipedia and Common Crawl data, I found myself with much more than 100 millions of tokens so I had to pick and choose the most relevant documents to train my model with. The goal of my methodology is to keep the documents that represent in the best way the native Korean language:
- I first performed a weak tokenization on my corpus to approximate the number of tokens I had by splitting the corpus on spaces.
- I removed all numbers, emojis, punctuation and other symbols that are not specific to Korean from my obtained tokens.
- I computed a counter of all tokens in my corpus and retrieved the top 70,000 mentioned tokens.
- Then I retrieved documents that mention most of the top used tokens such that my corpus would be built of 100 million tokens and there was my training corpus!
Now that we have our raw corpus of training we can start real business!
2 — Data tokenization
I guess when I told you earlier that I tokenized with a split function, you started thinking that this article was really a joke but let’s reassure you, this was never my end game!
First let’s remind you that no further data preprocessing is required for training a language model. A lot of NLP tasks perform some text stripping of numbers, stopwords, lowercasing, stemming … All of those would strip your text from its context and our goal is to learn to speak Korean so we must keep all our text as it was originally written.
To tokenize Korean text I tried two tokenization models:
- Korean spacy model that is a wrapper to Korean mecab tokenizer.
- sentencepiece subwords tokenizer model trained on my corpus with 28000 maximum tokens
As it’s recommended in the multifit article, I went with the second option to have a subword granularity.
3 — Training model
When training a language model as well as training any model, the two things that you want to avoid are underfitting and overfitting.
A model under fits when it is too simple with regards to the data it is trying to model. You can detect that when you find that your model cannot learn on your training data and that your training loss does not converge to 0 at all.
On the opposite, a model over fits when it learns “too well” to model your training data but that performance remains low on the test data. That is a sign that your model is not likely to predict well data that it hasn’t seen.
When I started to train my language model, at the beginning I was really struggling to learn anything from my data. As you can see on the picture below, after 10 epochs of training my training loss was not decreasing by an inch.
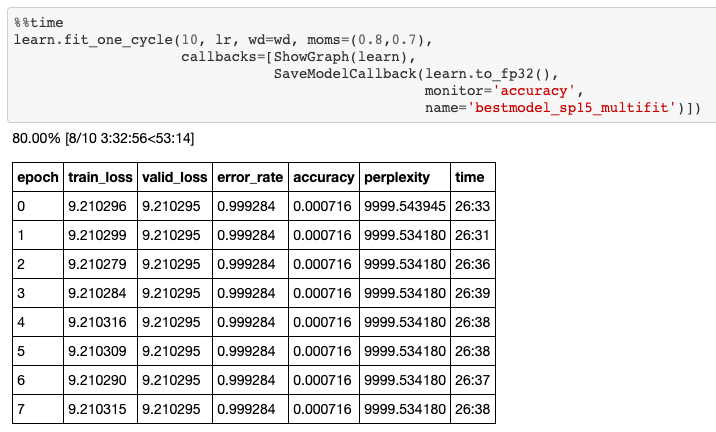
What it means is that my model was too simple to represent the complexity of Korean language.
Here is what I did to overcome this issue:
As you can imagine, debugging any deep learning model is not easy as there are so many degrees of liberty. You have to find the right network structure as well as the right set of hyperparameters.
To simplify the problem at the beginning, the right way to go is to try to overfit on a single batch of data. The idea here is to make sure that given some data, your model is able to interpret its complexity and perform well on the training set.
Here are all the things I tried :
- Increase embedding size
- Increase number of hidden layers
- Changing optimizer functions
- Changing learning rate
After lots of attempts, here is the structure and hyperparameters that allowed my model to start learning :
Neural network architecture:
- QRNN Structure
- Number of hidden layers: 2500
- Number of layers : 4
- Embedding size : 768
Once your model is able to predict correctly on your training set, the next thing you want to avoid is overfitting.
Here are some regularizations that I tried to make sure my model would not overfit.
- Add dropout
- Add weight decay
- Add gradient clipping
Here are the regularizers that I used for training my model:
- Learning rate: 0.0002
- Weight decay: 1e-8
- Gradient clipping: 0.25
Results
After training my model for 15 epochs, I finally reached an accuracy of 25% and a perplexity of 100. As I said at the beginning, I never intended to use my language model for text generation so I was already satisfied to know that my model is able to predict correctly one word out of 4.
Then I re-used my pre-trained model for text classification. The dataset I used is a balanced dataset made of 10k social documents coming from Instagram, Facebook, Youtube and websites that were labelled as “label1” or not “not label1”. My goal was to predict that a new publication is about “label1” or not.
Here are the performances I get for all the languages we developed:
Image for post
Performances of different languages text classifiers
So even without speaking the language and training the pretrained language model myself, the performances for the Korean text classifier reaches quite well the other languages performances.
I still have a lot of things that I should try to improve the performances I get but still, it was kind of a hail mary to learn to process documents of a complex language like Korean without understanding a word of it and without finding relevant information and advice on the web.
Next steps
I have just described how I could improve a Korean text classification model leveraging a simple language model made from scratch. The initial performance is already good but there is room for improvement. I think what I would like to work on in the short run would be:
- Proofread the tokenization: as I don’t speak a word of Korean, it would be interesting to have a native Korean speaker have a look at the tokenization and confirm that it makes sense.
- Enhance my language model and compare classification performances by:
- Transfer-learning a backward language model, as it appeared to have been more performant on English or French.
- Transfer-learning a bi-directional language model.
- Having dynamic learning rates during training to avoid being stuck in a local minimum.




