

Watch the replay of the workshop (in French) | To turn on English subtiles, click the "CC" icon and then click on "Settings". After, choose the "Subtiles" option and then "Auto-translate" to English or the language of your choice.
On 27 September at the Big Data & AI Paris 2022 Conference, Justine Nerce, Data Consulting Partner at Artefact and Killian Gaumont, Data Consulting Manager at Artefact, along with Amine Mokhtari, Data Analytics Specialist at Google Cloud, conducted a Data Mesh Workshop. Data mesh is one of the hottest topics in the data industry today. But what is it? What are its business benefits? And above all, how can companies successfully deploy it across their organizations?
Data mesh is a new organizational and technological model for decentralized data management. A distributed architecture approach for managing analytical data, it allows users to easily access and query data where it resides, without first transporting it to a data lake or warehouse. Data mesh is based on four core principles:
The workshop was divided into three parts:
- Business value: Why adopt a product/mesh approach? How does it serve the company’s business objectives?
- Deployment approach: How to achieve success? What steps should be taken and what organizational model should be used?
- Technology stack: Why choose Google as a technology solution?
To kick off the Business value discussion, Justine Nerce explained: “One of the best reasons for adopting a product/mesh approach is that it eliminates two vicious circles. The first is ‘reinventing the wheel’ each time a new use for data emerges: a new team is formed that creates its own data pipeline to serve its specific needs. The result? Zero shareability, zero reusability for the technologies chosen. The second is ‘building a monolith’ when a new use for data ends up in the backlog of a central data team, then gets handed off to non-data specialist teams that carry out massive data collection, generic transformation and use case development, with the risk of not responding to user needs.”
But with a product approach, the vicious circle becomes a virtuous one. When a new use for data emerges, instead of building something new, data mesh seeks out what already exists and can be reused. It identifies domains already in charge of handling given subjects and looks for existing data products that can accelerate the creation and development of new needs, either as they are or in iterative processes to create new, customized products. And all of these products can be published in the company catalog.
How data products create business value
Data products have existed in enterprises for a long time, but in data mesh, the uses and qualifications of data are essentially different, explains Killian Gaumont:
“Today’s data product is a combination of data made available to the business for business use and specific features that facilitate the use and the reusability of data”.
To be included in data mesh, a data product must be:
- Governed by a team of dedicated owners;
- End-user oriented and widely adopted;
- Of quality throughout its life cycle;
- Reusable as is or for building other products;
- Accessible to all users;
- Standardized so that everyone speaks the same language.
At Artefact, data products are categorized into three different product families. “There are raw products such as databases used for business processes – which are data products nonetheless”, assures Killian. “Next, there are data products enriched with customized algorithms or product recommendations, such as Interaction 360°. At the top are finished products aligned with use, such as dashboards. These are consumer-line products, designed to create value by linking product development to business strategy.”
Deploying data mesh across the enterprise
Artefact’s approach to data mesh deployment starts small, by prioritizing the business’s use cases and pain points. All the domains and data products needed for each prioritized business use case (from raw data to finished products) are then identified. A future team is assembled to develop the first products and set standards. Then, related products to be built in the future can be identified.
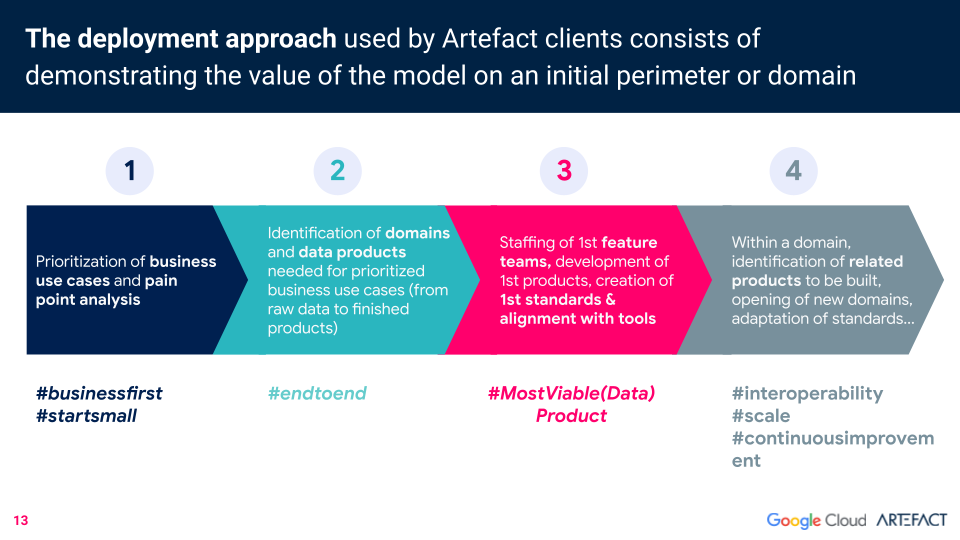
There are three prerequisites for data mesh deployment. The first: breaking down silos.
“If data mesh is to be a success, we must move towards an organizational model that breaks down the silos between IT, data and business to have platform teams composed of cross domain and cross product teams, across all entities”, says Killian. “It won’t happen overnight, obviously. But we’ve already begun breaking down silos by integrating business teams into IT data teams so that product teams developing data products can work more efficiently.”
The second prerequisite is the Data Product Owner, who plays a key role in coordinating data mesh implementation. The data product owner has three missions: to design, build and promote data products. The first two missions are self-explanatory; the third is equally important, as the strength of a data product lies in the fact that it is adopted and used by the business. “The data product owner is responsible for ensuring that the data product is documented, understandable and accessible to users, and aligned with business needs. The criteria of his success are his KPIs: usage, technical performance, data quality”, adds Killian.
The last prerequisite is that the business be able to clearly and continuously define its data domains and, once the model has proven its value, be capable of scaling up.
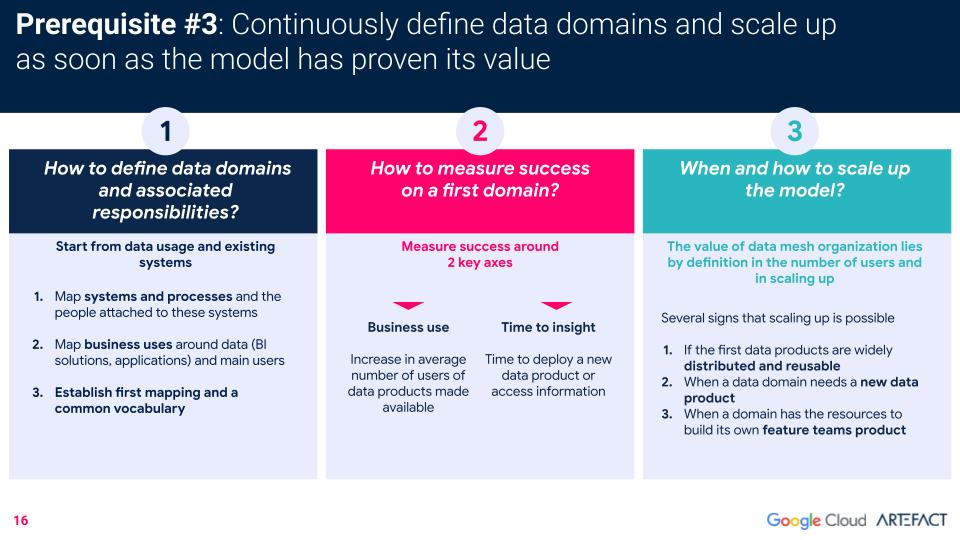
These are the three of the most frequently-asked questions by clients implementing data mesh, along with Artefact’s recommendations for successfully defining domains, measuring success, and knowing when it’s opportune to scale up.
The tech stack: managing data mesh with Google Cloud
“The first thing data and IT teams need to implement data mesh is the ability to make their data discoverable and accessible by publishing it in a data catalog”, begins Amine Mohktari. “To achieve this, Google has a first pillar, Big Query, which enables the creation of shareable datasets. The second pillar, the catalog itself, is made possible by Analytics Hub, which creates links to all the datasets created by various members of the organization or its partners so that subscribers may easily access them.”
“It’s important to understand that only links to data are made – never copies. Thanks to this system, subscribers can use data as if it belongs to them, even though it remains in its original physical location. This remains true even when you have data sets stored in a different cloud”, assures Amine.
User experience is a major principle of the system and is reflected in all aspects of data mesh, not only in facilitating data sharing and data composition, but by keeping data permanently available, no matter how many users are active.
As for data security and governance, Google has it covered with Dataplex, their intelligent data fabric that helps unify distributed data and automate data management and governance across that data to power analytics at scale. Along with an Identity and Access Management (IAM) framework to assign a unique identity to each data consumer, “Dataplex offers companies a set of technical pillars that allow them to carry out any implementation of governance in the simplest way possible”, explains Amine.
“At Google Cloud, our aim is to provide you with a serverless data platform that will allow your data teams to focus on areas such as processes and business use cases, where they have added value no one else can produce.”
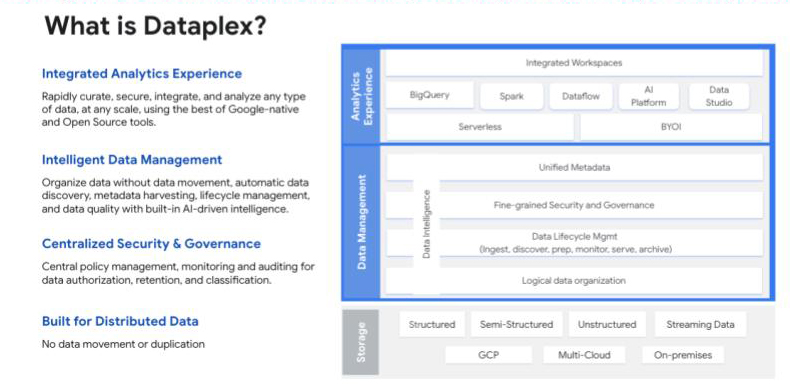
Google’s Dataplex gives users a 360° view of published data products and their quality
Conclusion: three pitfalls to avoid when implementing data mesh
DON’T > Stay stuck in a project vision instead of a product vision
DO > Define priority data products according to different uses;
DON’T > Scale up the new model too rapidly
DO > Test the model with a well-defined operating model;
DON’T > Deploy an overly complex technical ecosystem
DO > Keep the tech stack small to have as many players as possible.



